Introductory exercise on Using the ASReview Simulation Mode
Introduction
The goal of this exercise is to learn how you can perform simulations on a labeled systematic review dataset using ASReview LAB (the web interface), the command line interface, and the package titled Makita.
A simulation in the context of AI-assisted reviewing involves mimicking the screening process with a particular model. In a simulation setting, it is already known which records are labeled as relevant, and the software can automatically reenact the screening process as if a human were labeling the records in interaction with the Active Learning model. This allows you to answer questions about the (workings of) the model and compare the performance of different models under different circumstances. Read the documentation for more information about running simulations.
If writing scripts and running simulations is new to you, don’t worry, you can make it as simple or complicated as you want.
In this exercise, you will learn how to prepare, run, and interpret the results of a simulation yourself. You will first do this using the web browser with the click-and-run interface you know from the first exercise. Then you will be guided through the same process in the command-line interface, which has more options than the LAB interface. Lastly, you will run the same simulations, this time using the Makita package. This package automates much of the process, which is great for large-scale simulation studies.
Enjoy!
Conducting a simulation via the web browser
To start off easy, we will run a simulation study using the van de Schoot et al. (2018) benchmark dataset we also used in the introductory exercise.
For this exercise, we assume you have already installed Python and the ASReview LAB application. If you haven’t done so yet, you can follow the instructions on installation.
Open ASReview LAB with the terminal. Use the left hand menu to select the Simulation mode. Like before, select the DISCOVER tab and select the van de Schoot et al. (2018) dataset from the list of datasets. Download the dataset to start your new project.
Navigate to the Prior knowledge tab. Click Search and add these four relevant studies:
A Latent Growth Mixture Modeling Approach to PTSD Symptoms in Rape Victims
Peace and War
The relationship between course of PTSD symptoms in deployed U.S. Marines and degree of combat exposure
Trajectories of trauma symptoms and resilience in deployed US military service members: Prospective cohort study
Return to the previous menu. Verify the Prior knowledge tab. It should read Show records (4). Verify the four records by clicking show records. After verifying everything is in order, click Simulate to start your simulation.

During the simulation you will see a loading bar underneath the project. This will disappear when the simulation is finished. Open the project to see check out your fresh simulation!
Note: it can be that running the simulation takes a long time because of the size of your dataset in combination with the chosen model. To give you an idea of the possible differences in runtime between models, see Table 1 on page 15 of Teijema et al. (2023). Performing the feature matrix for a dataset with 15K records takes 20 seconds with TF-IDF, and 6 hours with SBERT.
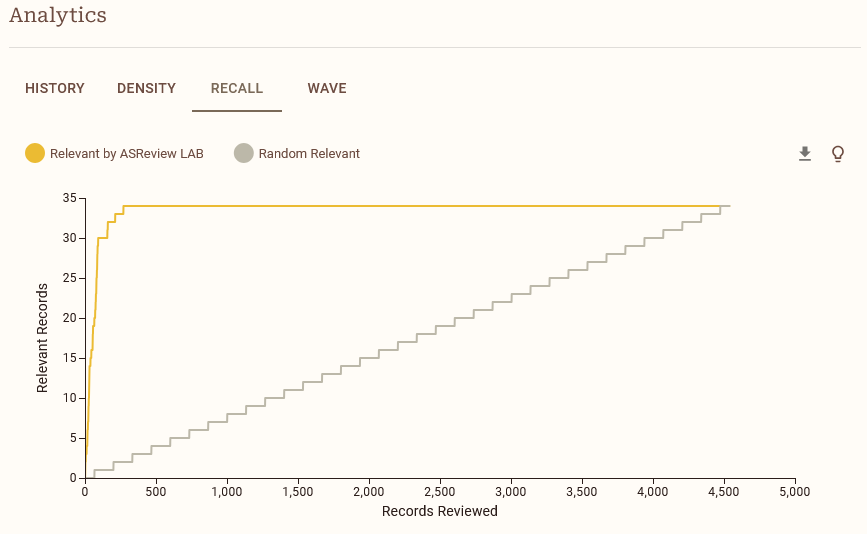
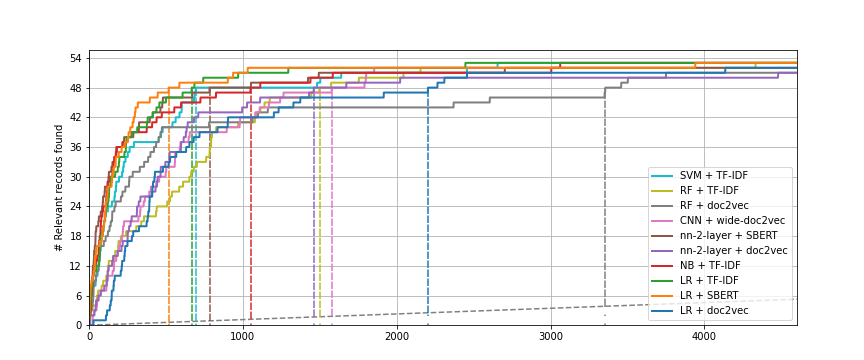
When the simulation is done, navigate to the Analytics panel and select RECALL. Save the recall plot to your laptop. After saving the plot, check out the other analytics options such as DENSITY and WAVE. Read the explanations of different options by clicking on the lightbulb icon. Try to understand what the different plots mean and how they can help you understand the performance of your model.
Woohoo! You just performed a simulation study! Easy right?
Model Comparison
Let’s compare the performance of different models. We will do this by running different simulation studies with the same dataset, but with different settings.
Start a new project (use a different name) from the same dataset, and add the same relevant articles as priors. This time, after selecting your Prior knowledge, navigate to the AI tab. Select the ELAS u3 model from the dropdown menu. This is a model that uses a different feature extractor and query strategy than the default ELAS u4 model.
Have you read the
AI Models Explainedsection revealed by clicking the lightbulb icon? If not, you can do so now to learn more about the different model types.

Run the simulation study and again save the recall plot.
Compare the recall plots. What is your conclusion in terms of performance for the different models? You might observe some differences in how long it takes each model to arrive at the total number of relevant records found.
Compare the Loss and NDCG metrics. Do you understand the differences in performance between the models? Check the lightbulb icon for more information about the metrics. Do the metrics match your observations from the recall plot?
Many papers have been written about such comparisons; for an overview of such comparisons, see the systematic review on this topic.
Conducting a simulation via the command line interface
Step 1: Choose a research question
Many more options for the configuration are available via the Command Line Interface (CLI). Read the documentation on the CLI to get started.
The CLI is useful because 1001 questions can be answered by running a simulation study and every simulation study requires slightly different settings. As example, we will work on three example questions.
In the second part of the exercise, you will also be introduced to some performance metrics that you can use to assess the performance of your model.
Research questions:
- When using AI-aided screening to find 95 percent of the relevant records, how much time did I save compared to random screening?
This question can be addressed by examining the Work Saved over Sampling (WSS) statistic at a recall of .95, which reflects the proportion of screening time saved by using active learning at the cost of failing to identify .05 of relevant publications.
- How much variation is there between three runs of the same model with different prior records selected for training the model?
This question can be addressed by running the exact same simulation three times, but with different prior knowledge selection. We introduce the metric the percentage of Relevant Records Found (RRF) at a given recall (e.g., after screening 10% of the total number of records).
- Does, for example, the ELAS u4 or ELAS u3 perform better for a given dataset, when keeping the other settings fixed? For this question, we introduce the metrics the Extra Relevant Records found (ERF) and the Average Time to Discovery (ATD).
To keep your results organized, we suggest you fill out the table below with your simulation results for each model you run.
Step 2: Create a folder structure
We recommend you to create a designated folder to run a simulation in, to keep your project organised. Create a folder and give it a name, for example “Simulation_study_PTSD”. Within this folder, create two sub-folders called ‘data’ and ‘output’. Also using NotePad (on Windows) or Text Edit (on Mac/OS) to create an empty text file called jobs.txt in the main folder. This is where you will save the scripts you run. See the example below:
Step 3: Choose a dataset
Before we get started, we need a dataset that is already labeled. You can use a dataset from the SYNERGY dataset via the synergy-dataset Python package.
Open the terminal.
Navigate to the folder structure;
You can navigate to your folder structure with:
cd [file_path]It’s also possible to open a terminal directly at the correct location.
For MacOS: 1. Right-click on created folder. 2. Click “New Terminal at Folder”. Then the data set will be automatically be put into the designated data folder. For Windows 11 (and sometimes 10): 1. Shift-right click inside the created folder. 2. Click on Open in Terminal
- Install the synergy-dataset Python package with: (This package will already be installed after installing ASReview, but better safe than sorry!)
pip install synergy-dataset - Build the dataset.
To download and build the SYNERGY dataset, run the following command in the command line:
python -m synergy_dataset get -o data You can also choose to use your own dataset. Do make sure that the dataset is fully labeled and prepared for simulation.
Step 4: Write and run the simulation script
Below you will find a step by step guide on how to run a simulation with the ASReview software. Depending on your research question, you will need to add or change things (e.g. run multiple simulations if you want to compare runs of the same model with different seeds or to compare different models question 2 and 3).
The parts between the brackets [ ] need to be filled out by you.
Open the Terminal
Navigate to the folder structure
Run the simulation
Now, we’re going to write the script to run your simulation, using the code below. You still need to fill out at least three pieces of information: the dataset’s name, the name of the output file and a seed value, to make the results reproducible. Some processes in ASReview require (pseudo-)random number generation. The user can give such a process a fixed “seed” to start from, which means the same sequence is generated each time, making any simulation reproducible. The --seed command controls the seed of the random number generation that is used after model initialization.
asreview simulate data/[name_of_your_data.csv] --output output/[results_name].asreview --seed [your favorite number]Save this script in the jobs.txt file you just made, to keep track of which code you ran!
You can also decide to supply more arguments, for example to employ a different model or to specify prior knowledge yourself instead of using --prior_seed to select random ones . If no model is specified, the software’s default active learning model is used.
Run the simulation by copy-pasting the code in the command line interface.
Step 5: Obtaining a recall curve and the metrics
For the next steps, you first need to install some extra extensions. You can do so with:
pip install asreview-insights asreview-makitaYou can get the recall plot with this line of code:
asreview plot recall output/[results_name].asreview -o output/results.png Run the code in the CLI (and put it in your jobs.txt file).
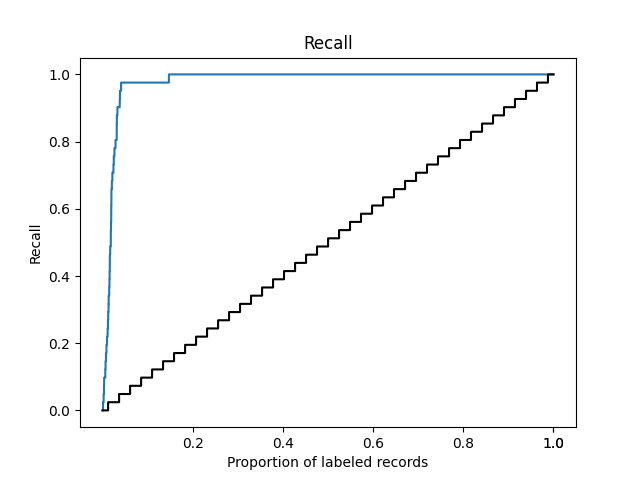
The plot file will appear in your output folder. Inspect the recall curve from the asreview-insights extension. It should look something like the figure below.
You can get the metrics with:
asreview metrics output/[results_name].asreview -o output/output.jsonThe output will appear in your command prompt and will be saved in the ‘output.json’ file in your output folder. You can scroll up in your CLI or open the file with a text editor like Notepad (or R, Python, or a Jupiter Notebook) to look at the metrics we got from the asreview-insights.
Fill out the performance statistics in your table under model 1. But what do those statistics mean? Check out the readme of the Insights packages.
Research Question 1
To answer research question 1, look at the WSS@95 statistic, reflecting the proportion of records you did not have to screen by using active learning compared to random reading, at the cost of failing to identify .05 of relevant publications. In the above example, we did not have to screen 65% of the records to find 85% of relevant records in the dataset.
Research Question 2
To answer research question 2, you can rerun the same model once more with a different value for --prior_seed. A different seed value will result in a different selection of prior knowledge.
Make sure to store the results under a different name and write the results in your table under Model 2.
Can you confirm that the model used different prior knowledge in this run using the information printed in your console?
Then, run the model a third time (Model 3), but this time specify a specific set of records to be used as training data by using the --prior_idx argument:
asreview simulate data/[name_of_your_data.csv] --state_file output/[results_name].asreview --seed [your favorite number] --prior_idx [row nr. relevant record] [row nr. irrelevant record] You should search in the data to identify the row numbers of the records you want to use. Be aware we start counting row numbers at zero (and mind the column names).
You can compare the three runs by looking at (for example) the variation in recall curves and the RRF@10 statistics. A higher percentage of Relevant Records Found after screening any portion of the total records (in this case 10%), indicates a more efficient model.
Research Question 3
To answer research question 3, rerun the model with the ELAS u3 model instead of the default setting:
asreview simulate data/[name_of_your_data].csv --ai elas_u3 --output output/[results_name].asreview --seed [your favorite number] --prior-seed [your second favorite number] You can compare the performance of the models by looking at the (for example) ERF and the ATD. A higher number of Extra Relevant Records found compared to random screening, indicates a a more efficient model. Conversely, a lower Average Time to Discovery means that the model was quicker to find all relevant records in the dataset.
Make it automatic
By now, you can probably imagine that writing the code for running many different simulations is quite time-consuming. Keeping track of everything you ran in a separate jobs.txt file to keep your simulations reproducible and manually filling out that table for comparison can also become cumbersome for large projects. Luckily we have automatized the process ofcreating a folder structure and writing many lines of code by using templates. For this, we use the package Makita: ASReview’s Make It Automatic.
If you want to take a look at the power of Makita, check out our simulation page!
With a single command, Makita generates a folder according to a reproducible folder format, a jobs script with all simulation commands and even a readme file! This way, your study is ready for the world right off the bat.
For the next steps, you first need to install the Makita extension. You can do so with:
pip install asreview-makita Getting started
Read the Getting Started documentation to get started with Makita. Follow the steps below to get familiar with the basic functionality of Makita.
Start with creating a new project folder. You can do this in the same way as you did for the CLI exercise. Inside the project folder, create a subfolder called data and put at least two benchmark datasets in the ‘data’ folder. You can copy files from the previous exercise, or use your own datasets.
*Note: if multiple datasets are available in this folder, Makita will automatically create code for running a simulation study for all datasets stored in the data-folder.*To create a study using the basic template, navigate to the folder and run the code:
asreview makita template basicThis command will create a folder structure with a jobs.bat file (or jobs.sh for Mac OS) in the main folder, and a README.md file. The jobs.bat file contains all the code you need to run your simulations, and the README.md file contains information about the folder structure and how to run the simulations.
Run the generated jobs.bat file. You can start the file by typing its name in the console, or by clicking on it for Windows. For Mac OS, typing jobs.sh in the terminal will do the trick. This will start the simulation.
After the simulations have been completed, explore the README.md file that has been created in your project folder. This file can be opened with a text editor and contains a navigation tree showing which output is stored where.
A big advantage of using Makita is that your project folder is already made fully reproducible and ready for publishing on your prefered persistent storage location! Also note that in contrast with the code you ran above, we did not ask you to set a seed. That is because Makita takes care of this too! Makita sets a default seed for you, which automatically makes your simulation study reproducible. If you prefer to set the seed yourself, for example to avoid long-term seed bias, you can still do so using the optional arguments.
Addressing the research questions
Now, we are going to address the research question(s), this time using Makita.
For this question, compare the WSS@95 statistic of multiple datasets. If you had not done so already in the above section, pick two or three datasets from the benchmark datasets and save them to the ‘data’ folder. Use the basic template to run your simulations and navigate to the output folder. You can find the WSS@95 of the simulation for each of your datasets in the ‘output/tables’ folder, in the file
data_metrics. Compare the WSS@95 statistics, for which of the datasets the metric is lowest?Suppose we are investigating the effect using different prior knowledge of relevant records, i.e.keeping the prior knowledge of irrelevant records stable. To answer this question, we can conveniently use the All Relevant, Fixed Irrelevant (ARFI) template. You only need one dataset in your ‘data’ folder, but you can choose to use multiple if you like.
Run the following code:
asreview makita template arfi 
Then run the jobs.sh/bat file.
NB: One simulation will be run for each relevant record in the dataset (with 50 relevant records, 50 simulation runs will be conducted; for each run the same 10 randomly chosen irrelevant records will be used), so this can take a while! Keep your CLI open to keep an eye on the progress, or go drink some hot chocolate.
The metrics can be found appear in the output folder. A recall plot summarizing all results can be found in the figures folder.
- Makita also contains a template to easily compare multiple models.
Run the following code:
asreview makita template multiple_modelsThen run the jobs.sh/bat file.
What else?
We introduced some basic templates, but you can answer many more different types of research questions using Makita by using customized templates, or adding new models.
If you like the functionality of Makita, don’t forget to give it a star on GitHub!
And if you want to look at even more information, larger simulations, cloud infrastructure? Check out this cloud repo.